AI's Billion-Dollar Lie: Is inference really profitable?
OpenAI, Anthropic, and Google keep dropping wild revenue numbers, but once you cut through the hype and wild speculations, the numbers don't add up.

You’ve probably seen the headlines. OpenAI is hitting $12 billion in annualized revenue. Anthropic’s climbing toward $9 billion. Google’s Gemini has 450 million monthly active users. The AI money machine is printing cash, right?
Wrong. And it’s not even close.
Here’s the uncomfortable truth that gets buried under the excitement: these companies are hemorrhaging money. Not metaphorically. Actually. Billions of dollars. Every. Single. Year.
OpenAI lost billions in 2024 and then burned another $2.5 billion in cash in just the first half of 2025—on about $4.3 billion in actual revenue. The math isn’t mathing, and increasingly, it looks like it might never.
The Smoke and Mirrors of Annualized Revenue
Let’s start with the magic word: ARR (Annual Recurring Revenue). This is how you get “$12 billion” from a company that actually generated $4.3 billion in six months.
When OpenAI claims $12 billion in annualized revenue, what they’re really saying is “if the run rate from our best month continued for 12 months, we’d hit this number.” That’s not actual revenue. That’s naive and, frankly, misleading extrapolation.
The actual numbers tell a very different story. OpenAI generated $3.7 billion in total 2024 revenue. In the first six months of 2025, they brought in $4.3 billion. Annualized, that’s roughly $8.6 billion—about 70% of the $12 billion headline run rate being hyped in the press.
Anthropic is playing the same game. Its mid-2025 run-rate was about $5 billion, guiding to $7-9 billion ARR (Sacra, PMInsights). But actual revenue is far smaller—roughly $1 billion in 2024 and about $2.2 billion projected for 2025 (Sacra Anthropic profile). The $5-9 billion ARR headline is the marketing number; the $2.2 billion is the cash number.
Google’s Gemini sits in a slightly different position. The company doesn’t break out Gemini as a separate business unit. Gemini is folded into Alphabet’s broader stack, which posted about $96.4 billion in Q2 2025 revenue and reported around 450 million monthly active users for the Gemini app (Adweek, AIM TV recap). But here’s the catch: Gemini isn’t generating standalone revenue. It’s cannibalizing existing search and cloud revenue while potentially increasing costs.
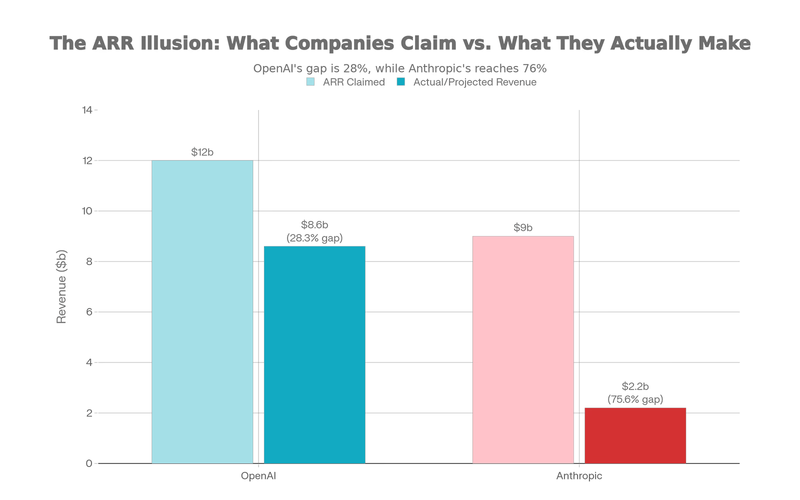
ARR run-rates dwarf real revenue.
The Cash Burn Reality That Nobody Can Ignore
This is where things get genuinely dark.
OpenAI’s situation:
- 2024 full-year revenue: about $3.7 billion
- H1 2025 revenue: about $4.3 billion
- H1 2025 cash burn: around $2.5 billion
Public reporting based on internal shareholder disclosures also points to multibillion-dollar operating losses and a target of roughly $13 billion in 2025 revenue with an $8-8.5 billion burn (Reuters / Yahoo Finance recap).
Leaked projections suggest cumulative cash burn through 2029 could reach $115 billion. Leaked internal projections, as reported by business press, suggest OpenAI doesn’t expect to be profitable until 2029 at the earliest, and even then, the projections are wildly optimistic.
They’re spending roughly $1.69 for every dollar of revenue they generate.
Anthropic’s burns:
Independent analysis of leaked financials suggests Anthropic lost on the order of $5.3 billion in 2024 while scaling ARR from roughly $1 billion to $5 billion (Where’s Your Ed At). Claimed 2025 loss: $3 billion—an estimate from a single leaked set of figures that industry skeptics already view as optimistic.
Current trajectory: Breakeven expected in 2028.
The difference is architectural. Anthropic is betting on enterprise customers and better unit economics. OpenAI is betting that building the most powerful AI and controlling the inference market is worth spending $115 billion by 2029. Neither path guarantees success.
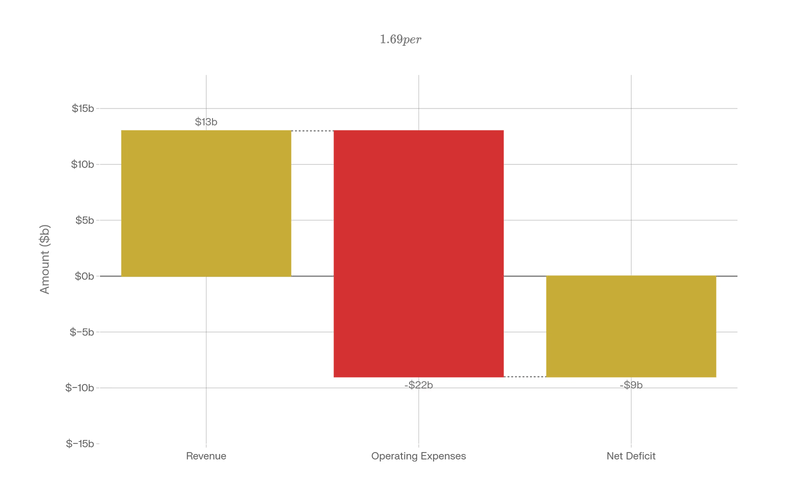
OpenAI 2025: ~$13B revenue vs ~$22B spend → ~$8B burn.
Why Inference Is a Margin Killer
Here’s the fundamental problem: AI inference (actually serving users with models) loses money at scale.
Training a model is expensive upfront but happens once. You pay $100 million to train GPT-4, and you amortize that cost across years. Inference, though, happens every single time a user makes a request. ChatGPT processes hundreds of millions of queries per month. Each one costs real money in GPU compute, storage, bandwidth, and cooling.
One widely cited breakdown estimates OpenAI’s 2024 inference costs in the low-single-digit billions, compared with roughly $150 million to train GPT-4 (Where’s Your Ed At). Do the math: inference costs 15x training for a single model over its lifetime and the gap keeps widening.
Yet OpenAI sells ChatGPT Plus for $20/month. That’s roughly $240 per year per user. If a heavy user makes 100 queries per month and each inference costs OpenAI anywhere from $0.01-$0.05 (a rough range pulled from cloud GPU/TPU pricing and third-party benchmarking), that’s $12-60 per year in compute costs alone. Push usage higher or assume costs nearer the upper end and the math collapses before staff, infrastructure, and R&D even enter the equation.

ChatGPT Plus revenue struggles to cover heavy-user inference.
This is the hidden truth: Nobody has figured out how to make AI inference profitable at consumer scale. Not OpenAI. Not Anthropic. Not Google.
Google’s TPU (Tensor Processing Unit) infrastructure hints at a potential solution: Google’s TPU v6e is marketed as delivering up to 4x better performance-per-dollar than high-end GPUs for LLM inference, and case studies like Midjourney’s reported 65% cost reduction moving from GPUs to TPUs (from roughly $2M/month to about $700K) illustrate how big the delta can be in practice (TPU economics explainer). But even Google doesn’t disclose Gemini as profitable. It’s strategic competitive positioning, not a profit center.
The Hardware Bottleneck: NVIDIA’s Stranglehold
Here’s where the ecosystem problem becomes apparent: the entire AI industry depends on NVIDIA’s H100 and A100 GPUs, and NVIDIA knows it.
Analysts estimate NVIDIA holds a dominant share of the AI accelerator market, often quoted at well over 70% by revenue (CNBC). The company has created an extraordinary situation:
GPU Pricing Reality:
- Manufacturing cost for an H100: Industry teardown estimates put H100 manufacturing cost a bit above $3,000 (Hacker News discussion of BOM cost)
- Retail price: Data-center buyers and resellers report street prices commonly in the $25,000-$40,000 range (coverage of H100 pricing)
- Secondary market: $30,000-$40,000 due to scarcity
- Cloud rental: $2.80-$7.00 per hour (depending on commitment and provider)
This is extraction masquerading as market clearing. NVIDIA isn’t just selling chips; it’s printing money from artificial scarcity.
The supply chain strain is real:
- Global H100 demand up 35% year-over-year despite prices near MSRP
- HBM (High Bandwidth Memory) production slots already sold out through 2026
- DRAM and NAND spot prices spiked dramatically: Contract prices for 16Gb DDR5 chips rose from roughly $6.84 to about $27.20 over Q4 2025—a near-300% increase tied directly to AI demand for HBM and DRAM (Intuition Labs DRAM report)
- Memory shortage forecasted through 2027, with NAND expected to face a 4.9-point supply shortfall in 2026
The AI boom is literally starving consumer electronics of memory. SK Hynix and Samsung have reallocated 20% of front-end DRAM capacity toward HBM (specialized memory for AI chips), leaving conventional DDR5 scarce.
That $27.20 spike? That’s the cost of AI infrastructure.
Meanwhile, smaller competitors are getting crushed. Companies without grey market access or relationships with cloud providers face “extinction-level threats” in their development cycles: unable to secure hardware, unable to train models, unable to compete.
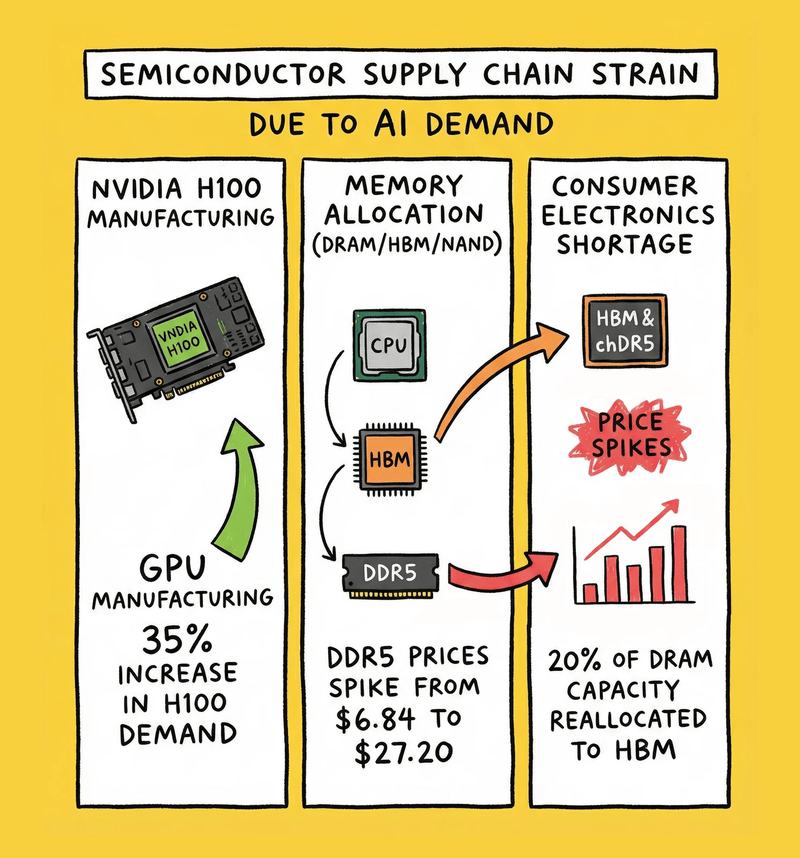
AI demand is soaking up GPUs and memory, squeezing everyone else.
When Specialized Hardware Becomes the Real Battlefield
Despite NVIDIA and AMD’s market dominance, for AI workloads, specialized chips outperform general-purpose GPUs at a fraction of the cost.
Google’s TPU v6e delivers 4x better cost-per-inference than NVIDIA H100s for LLM serving (per Google’s own positioning). On-demand pricing starts at $1.38/hour vs. $2.50+ for H100s. With commitments, TPU pricing drops to $0.55/hour. Preemptible instances offer 70% discounts. The economics are brutal for NVIDIA in pure inference scenarios.
A reported Midjourney case study illustrated the impact: by moving from GPUs to TPUs, the company said it reduced monthly inference costs from roughly $2 million to about $700,000, a 65% reduction that directly extends runway and accelerates scaling.
Groq’s LPU (Language Processing Unit) takes a different approach, optimizing specifically for LLM inference speed. Groq’s LPU cards, priced around $20,000, have demonstrated token throughput on Llama-class models that can double conventional GPU setups for certain inference workloads (CryptoSlate). While not cheaper per-unit than cloud TPU rentals, Groq enables on-premises deployment and avoids cloud vendor lock-in.
Cerebras CS-3, using wafer-scale architecture, claims (per Cerebras marketing) 21x lower end-to-end latency than NVIDIA’s Blackwell B200 GPU for inference workloads, while also delivering over 2x the tokens-per-second throughput of NVIDIA’s Blackwell-based DGX B200 for Llama-scale models. The system costs roughly one-third less for comparable inference capacity (Cerebras CS-3 vs DGX B200). These aren’t marginal improvements. They’re category shifts.
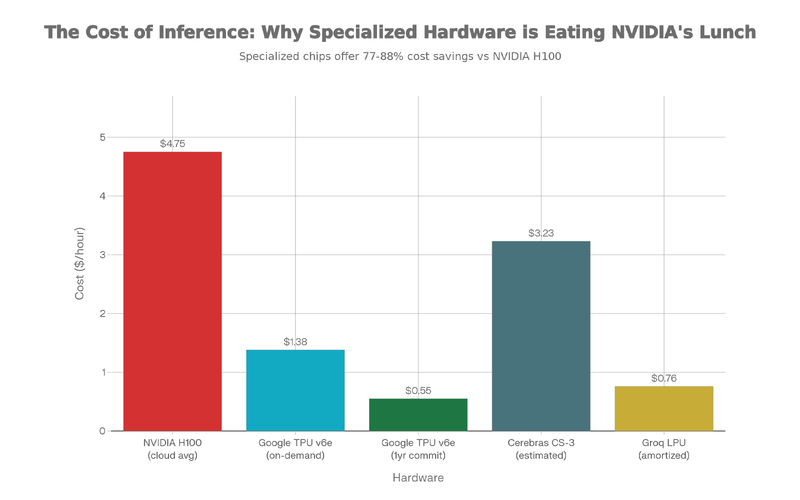
Specialized accelerators slash inference costs versus H100s.
The catch? These specialized chips only work for specific tasks. TPU dominates recommendation systems and transformer-heavy inference. Groq and Cerebras excel at LLM serving at scale. For training new models, diverse workloads, or research flexibility, NVIDIA GPUs remain superior.
But here’s what matters for the economics argument: if companies can migrate inference workloads away from GPUs, NVIDIA’s revenue base (currently $51.2 billion from data center operations alone in Q3 2025) becomes vulnerable. Not today. But the architectural path is clear.
The Chinese Alternative That’s Closing Fast
Western incumbents are comfortable assuming dominance. China’s approach suggests they should be nervous.
DeepSeek’s emergence changed the conversation. Founded by former Baidu researchers, DeepSeek R1 achieved state-of-the-art reasoning performance while training for reportedly under $5 million. OpenAI spent tens of millions on GPT-4. The cost differential is staggering.
Pricing advantage gets worse from there:
- DeepSeek R1 API: DeepSeek R1’s published pricing comes in around $0.14 per million tokens (DeepSeek vs ChatGPT cost comparison)
- OpenAI o1 API: versus about $7.50 per million tokens for OpenAI’s o1-mini—a roughly 50x difference
- Difference: 50x cheaper
For large-scale operations, this isn’t a marketing advantage. It’s existential. A breakdown for an e-commerce platform generating 10 million words a month shows monthly costs of about $100 with ChatGPT o1 versus roughly $1.87 with DeepSeek R1—around 98% savings (same source).
DeepSeek isn’t alone. Baidu’s ERNIE, Alibaba’s Qwen, Tencent’s Hunyuan, and ByteDance’s Doubao are all benchmarking competitively with Western models on suites like MMLU and HumanEval (Tech Buzz China on Chinese AI apps).
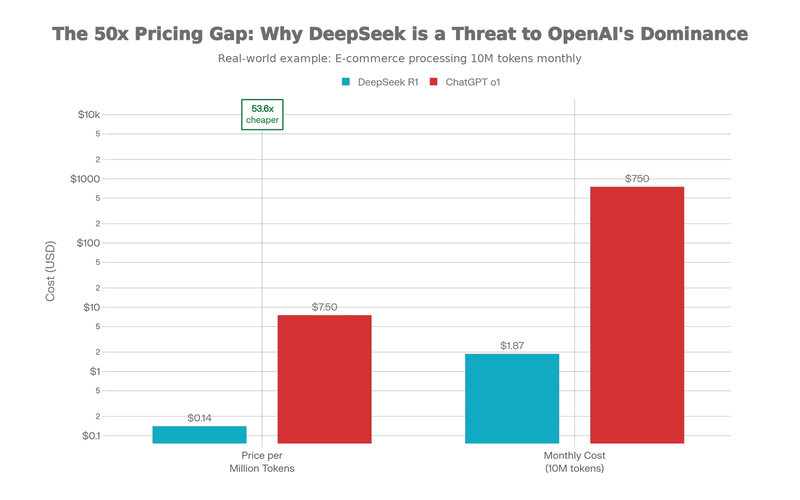
Chinese models compete at up to 50x lower per-token prices.
China’s Hardware Strategy
More concerning for NVIDIA: Huawei has publicly outlined a three-year roadmap for domestic AI accelerators aimed squarely at NVIDIA’s data-center business (Huawei AI chip roadmap), while fresh US export restrictions on the H20 are expected to cost NVIDIA about $5.5 billion in lost sales to China (CNN). NVIDIA CEO Jensen Huang acknowledged in September 2025 that “China is not behind” in AI development, calling the race “very close” and “a long-term, infinite race.”
Here’s what keeps strategists awake: if Chinese companies achieve cost-parity on model performance while maintaining 20-50x pricing advantages, the global AI market gets reshuffled. OpenAI’s valuation depends on being the undisputed best. If “good enough and 50x cheaper” becomes the market standard, valuations collapse.
The Amazon Parallel: Why History Doesn’t Repeat This Time
Every investor points to Amazon as proof that massive losses can precede profitability.
Amazon lost billions through the dot-com era—analysts estimate about $2.8 billion over its first 17 quarters as a public company—with 1999 alone seeing $1.6 billion in sales against a $720 million net loss (contemporary coverage, BBC retrospective). The company lost money for years while building logistics dominance, and when it finally turned profitable, it had created a moat that competitors couldn’t breach.
But the structures are fundamentally different.
Amazon’s losses funded:
- Physical distribution infrastructure (fulfillment centers, logistics networks)
- Customer acquisition in a winner-take-most market
- Marketplace ecosystem development
- These assets created lasting competitive advantages
Amazon’s path to profitability came from AWS: cloud services that generate 25-30%+ margins while subsidizing low-margin retail. AWS profitability eventually made the retail losses irrelevant.
OpenAI and Anthropic’s losses fund:
- Massive compute spending for model training and inference
- GPU rentals from NVIDIA (100% passed through to costs)
- Personnel (salaries doubled in 2025)
- Infrastructure (data centers)
The difference is critical: these costs never decrease. Every new model requires more compute. Every user added means more inference cost. Unlike Amazon building lasting physical moats, OpenAI is on a treadmill where the speed keeps increasing.
There’s no “AWS moment” coming for OpenAI unless:
- Inference becomes wildly profitable (it won’t be at consumer prices)
- Compute costs collapse dramatically (unlikely while GPU costs stay inflated)
- A higher-margin business model emerges (licensing? Nobody’s figured this out)
Amazon’s losses ended because the company built defensible advantages. OpenAI’s losses are structural. They’re baked into the unit economics of serving AI models at scale.
The Fundamental Math Problem
Strip away all the variables, and the equation is simple:
OpenAI 2025:
- Revenue: ~$13 billion (full year projection)
- Operating expenses: ~$22 billion
- Cash burn: $8-8.5 billion
- Spending ratio: $1.69 per revenue dollar
In other words, even under optimistic revenue assumptions, the core business currently burns about $0.69 for every dollar it takes in.
For comparison:
- AWS (AWS alone): ~$90+ billion revenue, ~30%+ margins, $27+ billion profit
- Google Search: ~$218 billion revenue, 50%+ margins, $100+ billion profit
- Microsoft (overall): positive cash flow, paying dividends
OpenAI doesn’t have a business model yet. It has a burn rate and a prayer that scaling eventually works.
Leaked internal projections, as reported by business press, suggest OpenAI is betting on explosive revenue growth toward the low hundreds of billions by 2030, combined with gradual margin expansion, to reach profitability around 2029 (Fortune analysis). If revenue doesn’t grow at 25%+ annually, or if margin expansion stalls (due to competition from DeepSeek), the 2029 profitability claim evaporates.
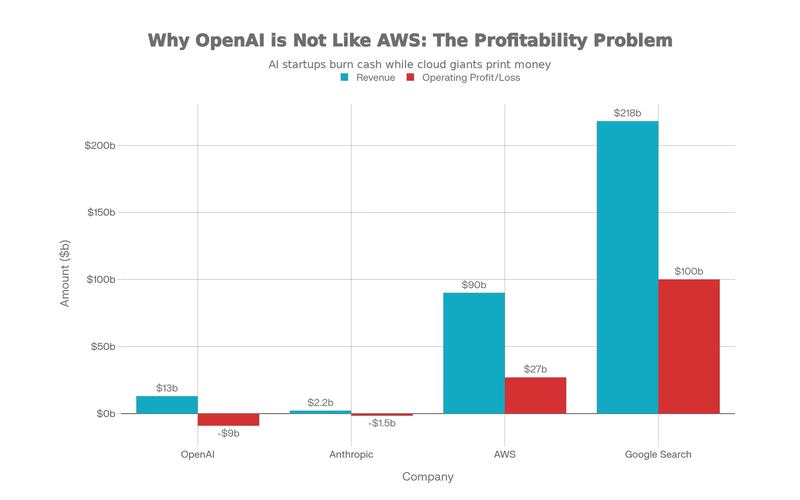
Amazon built moats (AWS); OpenAI rides rising compute costs.
The Uncomfortable Truth
The ARR numbers are real in the sense that customers are genuinely spending this money. OpenAI and Anthropic aren’t committing fraud. But they are optimizing their messaging around metrics that make their financial position look better than it actually is.
They have incredible products and real user bases, but the business model is fundamentally broken. They’re spending billions to serve users who pay pennies. The gap doesn’t close without either:
- Dramatically cheaper compute (5-10x improvements)
- Dramatically higher pricing (which kills adoption)
- External capital indefinitely subsidizing losses (which works until it doesn’t)
All three are possible. None are guaranteed.
So what?
As a consumer, treat today’s AI experience as a subsidized preview, not a stable utility. Prices, rate limits, and model availability will keep shifting until someone finds real margins. Keep a fallback: export your data, try an alternative model, and be ready to switch when the meter moves.
The companies building this future are brilliant, but until the economics catch up, the safest move is to enjoy the upside while staying portable enough to walk when the bill comes due.


